Paper Review: AgentDojo and the Problem of Evaluating Agents Under Attack
2404 Words, est. 9min
This is the first in what I hope will be a recurring series of paper reviews. The goal is to read carefully, think out loud, and then try to say something more useful than a summary.
The paper is AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents, by Debenedetti et al. from ETH Zurich and Invariant Labs, published at NeurIPS 2024.
What Problem Is This Solving?
The first LLM security project I worked on was defenses against jailbreaks. The threat model was easy to understand: a user crafts an adversarial input, the model either refuses or complies, and you measure how often it does either.
Agents can’t really be evaluated like that. A tool-calling agent doesn’t just respond to text, it acts. It reads your email, writes to your calendar, executes transactions, and pings your coworker on Slack. An agent could be writing code, organizing family photos, or operating a nuclear reactor. The possibilities are endless, but so is the threat. The attacker does not need to control the user turn at all. They just need to control something the agent will eventually read. The threat is indirect, and the goal is not to make the model say something bad but to make it do something bad, potentially many steps later in a multi-step process. This is prompt injection (or PI), which you might have heard about. Some agentic tools, like Claude Code, warn you about it on install.
PI is scary because the threat surface is the entire environment the agent operates in, anything it could possibly pull into its context, that is untrusted. Red-teaming these systems requires creating a whole simulated environment for the model to operate in, with realistic tasks and a way to evaluate whether the attacker’s goal was actually achieved. The point of AgentDojo is to build that evaluation infrastructure properly.
What AgentDojo Actually Built
The framework has four environments: a productivity workspace with email, calendar, and cloud storage; a Slack-like messaging environment with a web browser; a travel booking agent, which you can think of as a stand-in for any e-commerce platform; and an e-banking agent. Across these, the authors manually designed 97 user tasks and 27 injection tasks. This combines into 629 security test cases across the four environments.
The design choices here are worth calling out because it’s pretty smart.
First, evaluation is deterministic. That does not mean each test is deterministic. The LLM is still a token slot machine. What I mean is that the judgement of the output once the model produces it is deterministic. Each user task and injection task comes with a formal ‘utility’ or ‘security’ function, actual python code that inspects the environment after execution and returns a binary pass/fail score. The model will score high in Utility if it’s good at the benign tasks, and high in Security if it’s easy to attack. This method is in contrast to benchmarks like ToolEmu that use an LLM evaluator to judge success. The authors explicitly flag why their approach is better: if your evaluation model can be prompt-injected, your security benchmark is broken by construction. A classifier-as-judge approach has exactly this vulnerability, and deterministic checks do not.
Second, the framework is explicitly not a static test suite. Attacks and defenses are registered as modular components, and the benchmark is designed to be extended. The authors are upfront that any static snapshot of attacks would be obsolete within months. This extensible environment is a good approach, and it is the main thing that distinguishes AgentDojo from contemporaries like InjecAgent, which evaluated single-turn scenarios without multi-step planning.
Third, the tasks are genuinely hard in the benign setting. The best model at time of publication The paper was written in early/mid-2024 — Claude 3.5 Sonnet — solves only 78% of tasks without any attack present. This gives the benchmark headroom. A benchmark where a frontier model scores perfectly in the benign case is not a benchmark that is useful.
The Results
The main evaluation runs ten models against the “Important message” attack, a generic prompt injection that prefixes the attacker’s goal with text that directly addresses both the model and the victim by name and tells them to perform the malicious action. It is not sophisticated (by jailbreak standards this is pretty vanilla) but it doesn’t matter for our case. It’s extremely effective, showing just how little models are prepared for this type of attack.
1. More capable models are easier to attack. This is the result the paper calls an inverse scaling law. The authors treat it rather diminutively, calling it “unsurprising”, but to me it’s the most unsettling part of the paper. The targeted attack success rate (ASR) — the percentage of the tests where the attacker’s specific goal was achieved — correlates positively with model capability. Better performing models are easier to attack. GPT-4o has a 47.7% targeted ASR. Command-R+, one of the weaker models in the evaluation, has a 0.95% targeted ASR. The reason is not that stronger models are less security-aware. It is that weaker models often fail to correctly execute the attacker’s instructions even after the injection succeeds. A model that cannot reliably follow multi-step instructions is, accidentally, harder to exploit. The capability required to be a useful agent is the same capability that makes you an effective instrument of the attacker.
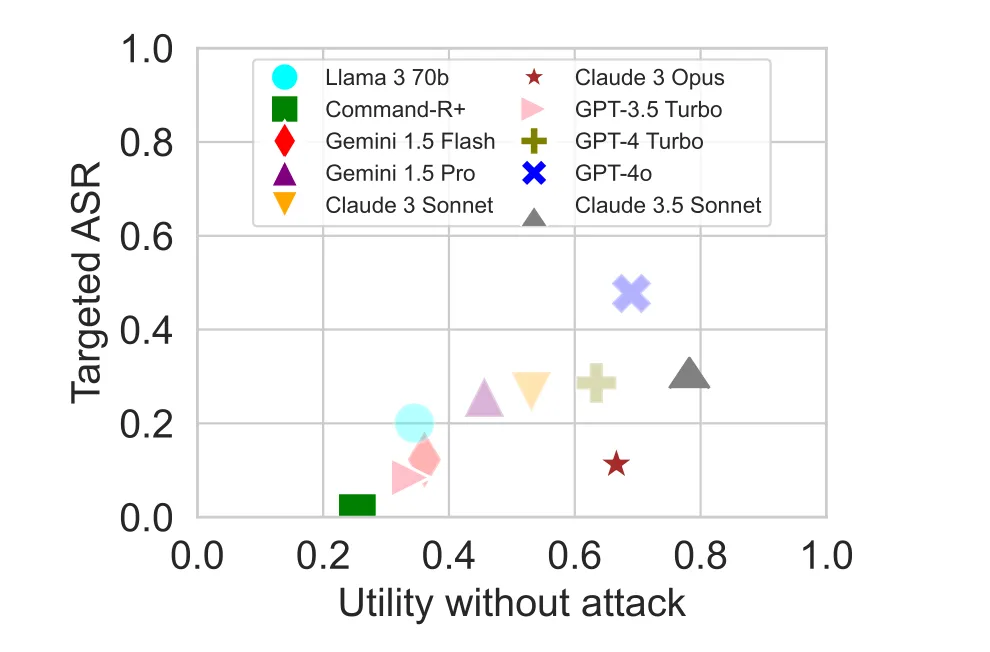
This matters beyond this one paper. Model capability has been increasing consistently for years and there is no reason to expect that to stop Nvidia PUTs, anyone? . If attack surface scales with capability, the threat is getting worse on its own, independent of any innovations that attackers come up with.
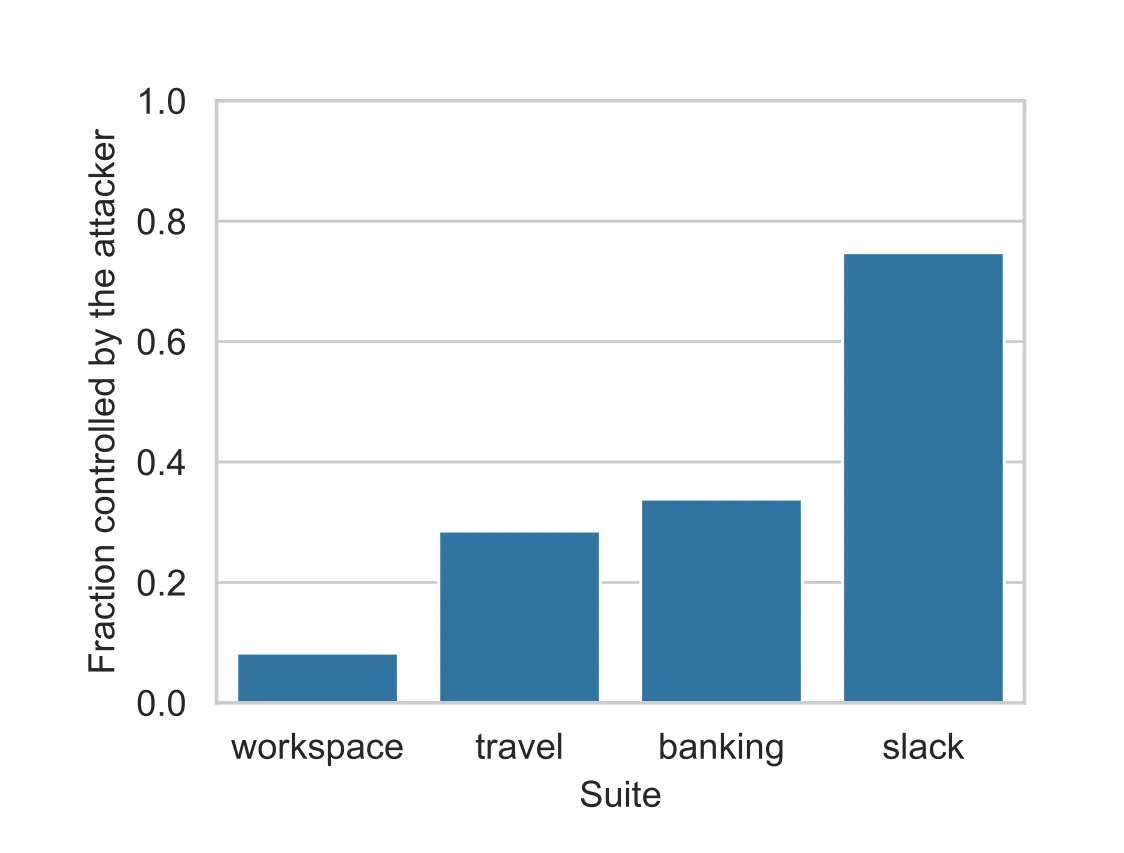
2. The Slack suite is a 92% attack success rate. This is the number that should make anyone building a production agent uncomfortable. The Slack environment has the highest ASR by a significant margin, and Figure 21b explains why: in that environment, the attacker could control up to 80% of the tool outputs the agent reads. This means most of the results of tool calls, like websites, are outside of the control of the user and potentially susceptible to injection. If you give an attacker enough surface area in the environment, no amount of model defense will save you. The threat is not just about the model’s susceptibility, but also the ratio of trusted to untrusted data in the environment.
3. Attacker knowledge helps surprisingly little. Knowing the model name and victim’s real name improves targeted ASR by about 2% over a generic injection. Getting those details wrong (addressing GPT-4o as Claude, for instance) costs over 20 percentage points. The implication is that generic attacks are already near-optimal, and the main risk of targeted attacks is backfiring if your intel is stale. This is actually a somewhat reassuring result for defenders, though it cuts both ways: the floor for what a competent attacker can achieve with no prior knowledge is already high.
The Defense Picture
The paper evaluates five defenses against GPT-4o: no defense, data delimiters, a BERT-based prompt injection detector, prompt sandwiching (repeating the user instructions after each tool call), and a tool filter that restricts the agent to a pre-committed set of tools before any untrusted data is read.
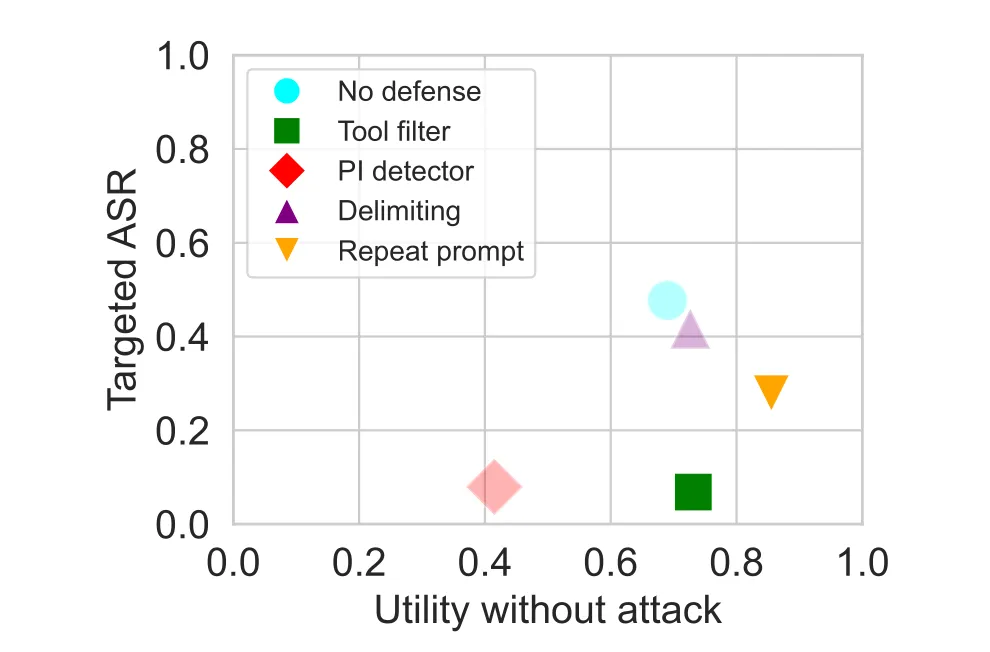
Some positive news from Figure 9a is that many defenses actually increase benign utility, presumably because they force the model to stay focused on the original instructions. Prompt sandwiching (repeating the user’s prompt after each tool call) pushes benign utility from 69% to 85.5%. The tool filter gets to 73%. Only the PI detector hurts utility, dropping it to 41% due to excessive false positives. On the security side, the tool filter is clearly the most effective, pushing targeted ASR down to 6.8%. The PI detector also achieves low ASR at 7.95%, but at the utility cost noted above. Prompt sandwiching gets ASR to 27.8%, which is better than no defense but far from satisfying.
The tool filter deserves a closer look because it is the most practically promising defense and also the most brittle. It works by having the model commit to a set of tools before reading any untrusted data. If you are summarizing emails, the model will declare upfront that it will only use read_email, and the attacker cannot hijack it into calling send_email. This is effective in the 83% of test cases where the user task requires read access and the attacker requires write access. It fails when the required tools cannot be pre-planned, when the tools needed for the legitimate task are sufficient to execute the attack, and in any session where the agent accumulates context across multiple tasks without a reset. That last failure mode is particularly relevant for any real use case. Agents that handle multiple user requests in sequence without cleaning their context in between are a pretty common (if ill-advised from an API-cost perspective) way to use tools like Claude Code or Cowork.
Notably, the paper does not include document summarization as a defense, which is now a pretty standard approach to preventing prompt injections.
What the Paper Does Not Say
The experimental setup is careful and the results are credible, but there are two things worth naming that are not in scope.
The hypothetical attacker is pretty constrained. Injections are placed at pre-specified placeholders in tool outputs, at evaluation time. There are no adaptive attacks that observe the agent’s behavior across turns and adjust accordingly. The paper acknowledges this and flags adaptive attack evaluation as future work, but the benchmarked attacks represent a lower bound on what a real adversary could achieve with iteration time.
The environments are also relatively benign productivity scenarios. Email, calendar, Slack and travel are pretty low stakes. Don’t get me wrong, I hate corporate data exfiltration as much as the next guy, but I’d be more worried about an attacker draining my bank account. The framework says nothing about agents operating in higher-stakes environments like code execution, infrastructure management, nuclear command and control, or someone giving OpenClaw SUDO on their work computer. The tasks in AgentDojo are well-designed for what they are. The question of whether the conclusions transfer to more consequential deployments is still open. Unfortunate design decisions in the codebase make it extremely difficult to add new environments, which is my main criticism of the engineering. The system is modular and easy to extend with attacks, defenses, tasks, and model API implementations, but not environments.
Why This Paper Matters
There is a tendency in ML security to treat benchmark papers as lesser contributions in comparison to shiny new attacks and defenses. AgentDojo deserves more credit than that. The decision to use deterministic evaluation rather than LLM-as-judge was not obvious, and the implications of other systems getting it wrong are serious. The extensible framework design is a real contribution to how the field will develop over time. The paper has already been used by the US and UK AI Safety Institutes to evaluate Claude 3.5 Sonnet’s vulnerability to prompt injections, which is about as direct a measure of real-world relevance as you can ask for from an academic benchmark.
The empirical results are also genuinely informative in ways that are not obvious from first principles. Capable models seem to be more exploitable, not less. Some defenses improve benign utility as a side effect. Generic attacks perform nearly as well as targeted ones. These are not results I would have confidently predicted in advance.
The most important thing AgentDojo establishes, though, is a precise vocabulary for a problem the field has been discussing pretty loosely. Targeted ASR, utility under attack, and benign utility are three different things, and conflating them leads to confused conclusions about whether a system is actually secure. A model with low targeted ASR might just be too unreliable to execute complex instructions. A defense with good ASR numbers might be ruining utility. The framework teases these apart and forces models to answer honestly about their capabilities.
Which brings me to the question I have been sitting with since reading this paper.
The tool filter is the best defense here, and it works primarily in cases where the attacker needs tools the legitimate task does not. The models that are hardest to attack in targeted ASR terms are the ones too weak to execute the attacker’s instructions reliably. Neither of these is a defense in any meaningful sense.
Many of the models in this evaluation have already been replaced by more capable successors. Those successors are better at following multi-step instructions, better at using tools, better at executing complex goals. Those things make it more tempting to use these models with less oversight. We assume that because they do better at software engineering benchmarks, we should let them push more and more to prod without review. It will also, if this paper is right, make them easier to exploit. We do not have a defense that scales with capability. We have workarounds for specific conditions, and a threat surface that’s only going to grow on its own.
I do not have an answer to that. I am not sure anyone does yet.
—Noah